Large Language Models in AppSec: An Innovator’s Primer
LLMs are a critical tool for saving time and scaling elements of any security program.
Travis dropped
A steady stream of Fear, Uncertainty, and Doubt surrounding Large Language Models (LLMs) dominates the discourse; Leaking IP? Generated code with vulnerabilities? Verbatim extracts from GPL code? Will OpenAI employees learn about your top-secret plans? Will LLMs usher in a new era of cyber-threats? The coverage here is massive - under-amplified is where AI, and LLMs specifically, is posed to make a significant impact on how people and organizations approach application security.
There’s certainly a lot to worry about - but here I want to focus on where engineers and leaders ought to look for, and encourage innovation in, areas LLMs can make an outsized impact on historically difficult problems.
I have enjoyed a career that has allowed me to study new technologies, and help folks understand their impacts on work - and security - in that time I’ve found one of the best ways to really understand the impacts of tech is to use it. Over the past 3 years I’ve followed the evolution of GPT models. Dabbling changed to full-on investigation with the first release of ChatGPT. I’ve been exploring LLM with experiments to carry out actual tasks, followed work in published literature, and checked out popular open source projects - all to build a practical understanding of where this technology is and where it might take us - and I created and released my own tool for solving practical tasks using LLMs, ThoughtLoom, in April 2023.
This article will equip you with an understanding of where and how LLMs will improve the business of application security; I introduce a map of where and how LLMs are able to make an impact on the business of application security for the better, cover practical concerns for making them useful to those tasks, discuss an emerging architecture for realizing those benefits at scale, and finally where we can start making a difference today.
Areas of innovation
While addressing the risk directly introduced by LLM use is attractive, and likely lucrative, we also find that this technology promises to help us reduce security risk in newly scalable ways. They aren’t great at everything, for example, they (for now) can be pretty bad at doing math - they also aren’t a great replacement for search engines (without agents). The core competency today is in tackling language tasks. Including translation - translation can mean code to written descriptions, and whether a written description satisfied some other written conditions. A lot of computing boils down to language tasks, what does a compiler error mean? How could it correspond to written code? How does that relate to my intentions? Well, that’s a lot of translation. It is exactly this ability to translate between expressions of language, code, behavior, and higher-level ideas about performance, like written policies - or attack objectives, which opens up exciting, and previously untouchable, domains for innovation.
Now, we can tackle many tasks that currently rely on expert analysis from limited / expensive folks, which boil down to a knowledge base and excellent reading comprehension, and scale it for the simple cost of some clever prompts, savvy context, and GPU server / API token credits. That’s expertise that is some of the most expensive to find, one the hardest to hire for, difficult to train, and increasingly in demand. We’ll cover that in three sections, first - where the rubber meets the road, how LLMs can be used directly by security engineers and other information security professionals to dispose of risk to assets, then - in an initiative, how LLMs can help an organization guide its security effort and understand its posture at scale, and finally the nuts-and-bolts reality of using LLMs to accomplish these types jobs.
(Dev) Security Operations and Engineering
Many of the immediately apparent applications of LLMs are close to the daily routines and tasks carried out by limited security staff at organizations. The space for innovation here to help individual engineers scale their expertise up and across portfolios of assets is exciting.
Codebase, Artifact, Project Understanding
LLMs can generate comprehensive behavioral descriptions by analyzing various artifacts. They can infer developers’ intentions from assembly code, interpret telemetry output like nmap results, file system contents, and traffic flows between components, and provide explanatory insights. Security engineers can leverage LLMs to ask risk-related questions at scale by loading repositories into embedding stores and reasoning over entire populations of source code.
Here’s just a simple example of chaining together several LLM calls to reason about some piece of code;
First, we’ll get a summarized interpretation of some chunk of code - in practice, you would generate summaries by walking the LLM through a whole repository, and providing in-context details via embeddings to enrich these queries;
>>Tell me what the developer likely intended to do, at a high level, then write a summary for security analysts;
>>func executeCommand(w http.ResponseWriter, r *http.Request) {
>> r.ParseForm()
>> command := r.Form.Get("command")
>> args := strings.Split(r.Form.Get("args"), ",")
>>
>> cmd := exec.Command(command, args...)
>> output, err := cmd.CombinedOutput()
>> if err != nil {
>> http.Error(w, err.Error(), http.StatusInternalServerError)
>> return
>> }
>>
>> fmt.Fprintf(w, "Command executed successfully. Output:\n%s", string(output))
>>}
>>
>>func main() {
>> http.HandleFunc("/execute", executeCommand)
>> fmt.Println("Server is running on port 8080...")
>> http.ListenAndServe(":8080", nil)
>>}
The developer likely intended to create a basic web server with a single endpoint (/execute) that would accept HTTP POST requests containing a "command" and "args" in the form data. The server would then execute that command, using the provided arguments, on the local machine where the server is running. The output from the command execution is then sent back as the HTTP response. This function could be intended for a debugging tool, remote server management, or running automated tasks.
Summary for Security Analysts:
The provided code snippet describes a server with a command execution vulnerability, potentially leading to Remote Code Execution (RCE). The vulnerability lies in the /execute endpoint where it takes the user input from the HTTP POST request directly and passes it to exec.Command without any sanitization or validation. …
Now we can interrogate this particular code and context with our canned battery of threat modeling questions;
>>Does this code rely on AWS S3 buckets?
No, the code you've provided does not rely on AWS S3 buckets. There are no mentions or dependencies on any AWS service, including S3, in the provided code.
>>Does it have any data-stores or other storage functionality?
The provided code snippet does not appear to have any data-stores or other storage functionality. It does not make use of any databases, files, or in-memory data structures to store data. The functionality is purely request/response-based, where it takes a request, executes a command based on that request, and returns the result of the command execution in the response. There's no evidence of data persistence between requests in this specific code.
>>Does this code require an Authentication mechanism?
Yes, this code certainly requires an authentication mechanism. Currently, the HTTP server listens for requests and blindly executes any commands provided via the "command" parameter in the form data of a POST request to the "/execute" endpoint. There's no user validation or authentication in place, which poses a major security risk. Any client that can reach the server could send requests to execute arbitrary commands, leading to a severe Remote Code Execution (RCE) vulnerability.
Threat Modeling
Threat modeling, for me, involves a process of understanding a systems’ goals from a business objective, mapping out the components responsible for them, and recursively identifying system and performance criteria down to the minutia of the implementation. Then we pass down what-ought-not-happen from the top - map them to how components can go wrong - and then get to the nitty gritty engineering decisions that protect our systems from those events.
Following from our code-understanding example, it’s obvious how LLMs can automate significant parts of threat modeling, a task traditionally resistant to automation, due to their ability to reason about human-stated intentions, code, and dictated security policy. To make this more useful, consider the impact of loading documentation, user stories, development initiatives and so on into an embedding store - and laying LLMs and embeddings lookups to incorporate those bits of text as context to enrich a description of individual pieces of code in a repository.
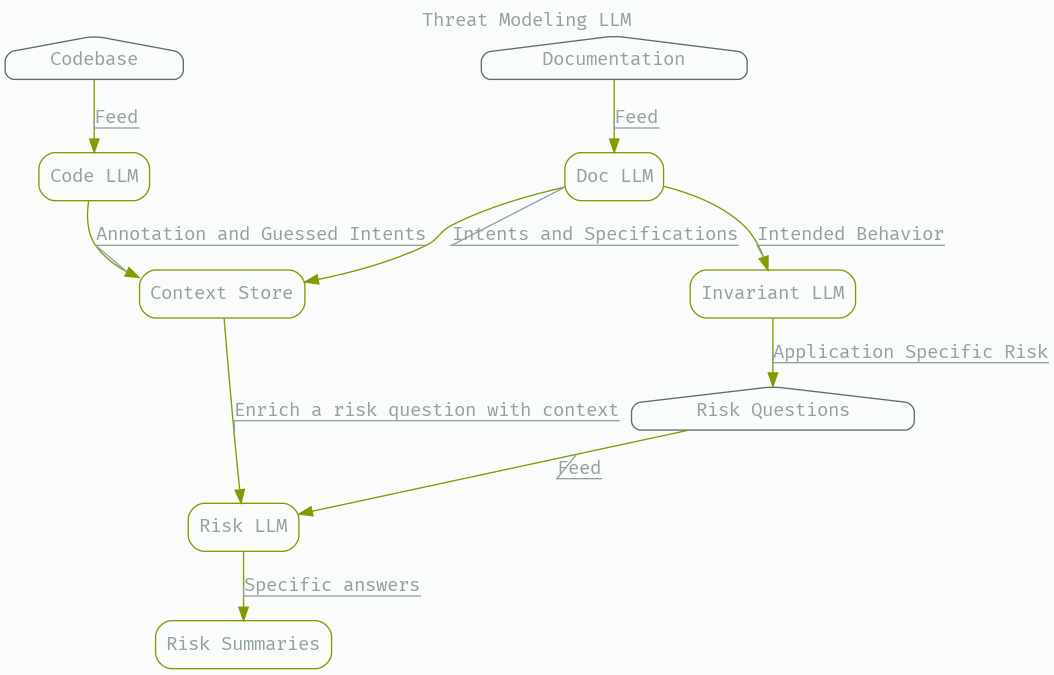
This type of system can be used to create a set of questions derived from these bits of context to augment our canned queries. Not totally dissimilar to what a human practitioner would do.
Bug Response
With modern systems it can be very difficult to pinpoint the specific components, let alone the lines of code, responsible for a failure - especially when the bug comes from bug bounty or other testing against live systems. Modern software is built on the backs of 3rd party services, sprawling architectures that can be multi-cloud, and a flow responsible for a bug may involve the interplay of 3 or more components. This analysis takes a lot of domain specific knowledge, and a lot of time and effort for everyone.
Embedding enabled search - with access to code, documentation, and other relevant artifacts - can retrieve details that an LLM needs to reason about what components and specific lines of code are responsible for some failure. Worst case you’re giving the team of humans some starting points for their investigation with any bug report. Best case you reduce your mean time to resolution from days to hours or, eventually, minutes.
Vulnerability Reporting
Much of the time spent in doing any sort of cyber security work in the trenches involves, after triaging individual results, transposing and tailoring tool output into atoms of reports that folks can use to decide what, how, and when to fix issues they uncover. Even if a report is a mix of tool and manual finding, often you need artifacts that help governance or business oriented staff and those for engineering staff that are very different from those immediately generated by security engineers and their tooling.
LLMs can generate tailored descriptions of identified issues, reducing the time spent on writing reports. They can reason over a population of findings and extract summaries automatically, shifting the engineer’s role from writing to improving and scaling resilient engineering through automation. Your LLM can be equipped with policy following hints, examples, and so on to tailor that to the way your organization likes to talk about vulnerabilities.
An example of report generation built on top of my tool, ThoughtLoom; nuclei2results
Public Research Review
Staying up to date with the latest in public news and events is a serious task, and there’s a lot of cool news that comes out every day - but not all of it is novel, unique, or useful to you or your mission. A system of bots can consume the signals from mailing lists, Twitter, RSS feeds, and news outlets to stay updated on published work, tailoring those insights to your asset population through LLMs - at the very least these systems can provide timely alerts to folks that need it most, via email, jira, or slack alert.
Bug Fixing Automation
An unfortunate side-effect of specialization in defect discovery is that the team that finds an issue often can only provide generic advice about resolving it. Maybe they just don’t have the expertise to come up with a tailored solution given your technology stack, maybe they don’t have the time, or they may not even have the resources to do so. Following on from ‘bug response’ we can go a step further - once a root cause has been identified we can use an LLM to suggest patches and changes in response to a security defect. Incorporate unit, integration, behavioral testing to look for breaking changes. An LLM can also provide more tailored guidance and assessment to those tasked with making or accepting a change - all things that improve engineers’ experience. Preliminary performance against static analysis code findings results in 25-40% success and acceptance with certain types of code - techniques like Tree of Thoughts and perhaps policy following with feedback from automated testing batteries will vastly improve performance here.
A simple example of automated bug fixing built on top of my tool, ThoughtLoom; semgrep2fix
Framework / Library / Platform Modeling
Much of the work involved in modeling some new library, SDK, framework, or platform is just good reading comprehension, elbow grease, and a critical eye for where a developer’s use of some API could materialize as something classed in lists like the Common Weakness Enumeration (CWE). Many security tool vendors employ dozens to hundreds of people that just do this. It’s a big job, given that the production of libraries and platforms doesn’t slow down, and those vendors’ customers’ adoption of them is unpredictable. LLMs can assume the perspective of an expert reader; producing a first pass over whatever frameworks or libraries are in use in your projects and even generate initial rules for tools like Semgrep to identify resultant risks.
End-to-End Testing
Contemporary defect discovery relies on several methods for achieving coverage of a target system - but they’re mostly pattern and heuristic based. Because automated exploration strategies (and rarely used strategies like concolic execution) fall down when presented with complex domain specific workflows (like filling out a multi-step application form) folks usually rely on tool-operators to walk through these tricky parts of a program or web-app by hand. While automated capture and replay technology is help here it is clear that LLMs can create and execute multi-step plans to explore complex application workflows, a key component in most dynamic analysis that remains difficult for automation, LLMs are able to walk dynamic analysis tooling to parts of applications that traditional spidering cannot. Work on getting an LLM to pilot themselves around synthetic and real world environments to achieve specific, but human understandable goals, is overflowing - commercial tools like adept.ai and open source results like Voyager: An Open-Ended Embodied Agent with Large Language Models touch on how powerful these tools really can be.
Security Initiatives
Just as exciting as the innovation space for security folks in the trenches are the prospects of being able to layer LLMs on top of other LLM outputs to generate insight that’s useful to those piloting, directing, and measuring security initiatives to achieve organizational risk management objectives.
Risk Assessment
Hierarchies of LLMs can roll up the results of risk assessments, security engineering behavior, developer behavior, at the repository, project, business unit level - and plain english insights into what’s working well, and what isn’t.
Look to LLMs to boost signal over populations of risk posture and identify trends across projects that attackers might exploit by combining attack surface discovery with business context.
Security Policy Review
We can use this technology to translate and map external requirements, such as NIST SDF or PCI, to internal standards and policies, identifying gaps or inconsistencies. They can also turn written policies into code that flexible security tooling can leverage, possibly even generating semgrep and nuclei templates to identify issues.
Combined with codebase understanding, you can understand what policies apply to what projects, where, and what assurance you have around compliance.
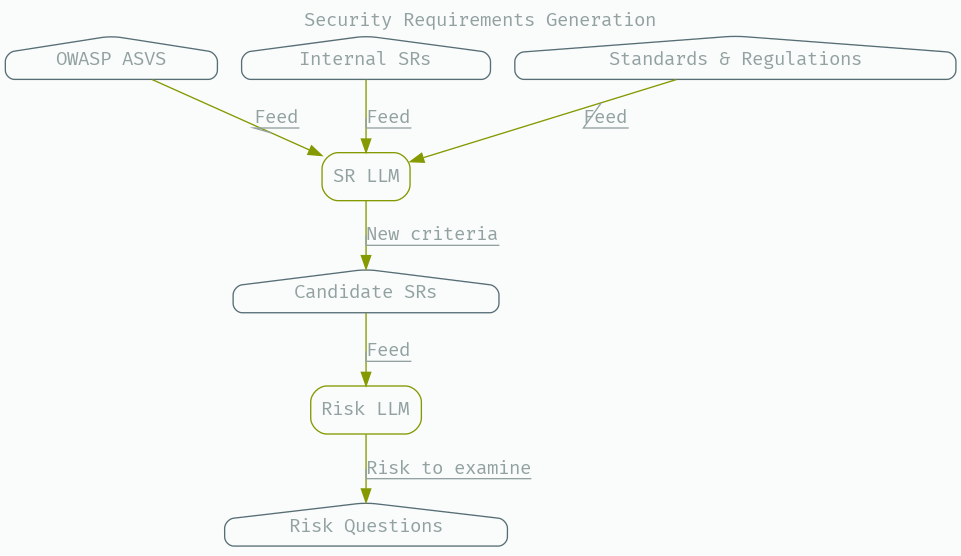
An example of simple policy synthesis is built on my tool, ThoughtLoom; semgrep2policy.
Incident management
LLMs can be used to bring human readable intelligence to evolving incidents - such as the discovery of a new CVE, or the exploitation of a bug - with access to context and a set of prompts that help the LLMs surface information that engineers and executives need in real time.
Scaled virtual satellite
We can provide a virtual satellite, or a security savvy engineer peer familiar with security policy and standards, to every developer. With prompt design and context, your ability to scale policy guidance, or change policy, becomes a matter of updating context datastores with current versions. Satellites aren’t limited to chat interfaces, they will also become part of code-generation loops - suggesting a particular design pattern, library, or secure method of achieving developers’ stated goals.
Initiative planning
LLMs can be equipped with a guiding philosophy for security, and context specific to your organization, including metrics, defect discovery results, policies, and code-bases, to support open-ended conversations about status-quo, what to focus on next, or how to solve problems. That same information and architecture can be used to provision instant or weekly fixed insights for leaders and their lieutenants.
Working with LLMs
Out of the box LLMs have a perspective space that includes, for the purposes of this article, essentially everything on the internet. Maybe a prevalent attitude is ‘just firewall, joe’ - well, that might be popular in the training corpus, but that’s not what we need. So, to make them useful to us, you do what many are referring to as prompt engineering.
Prompt engineering gets the LLM into a certain part of its generative space - one that ideally mimics an expert performing a task that you want to scale. The underlying models have a lot of information, and they can synthesize much of it, but in many cases context from your data is important to help the model accomplish a task as an expert would. The Prompt Engineering Guide is a good source to consult on the task of forming a convincing prompt.
Techniques like few-shot examples, chain of thought prompting, tree of thought, and in-context learning are the emerging techniques for helping LLMs achieve complex tasks.
Finally, some of the most exciting recent work combines these techniques with an agent architecture, and that lets LLMs plan and execute external services to carry out activities using ‘agents’ that it deems can do a better job, a good introduction to this is HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HuggingFace.
Aside from the mechanics of getting an LLM to do what you want, with the information you want, and using tools you provide, you have to decide among an increasingly large set of LLMs - hosted APIs from OpenAI, enterprise counterparts on Azure, Googles, or Anthropic, in-house deployment of Mosaic’s, and many many more that are being released every day. You can find a good list of privately deployable LLM models with permissive licenses here; Open LLMs and you can check the leaderboards for LLM performance here; LMSYS LLM Leaderboard.
I’ve used a ‘development loop’ of the OpenAI Playground plus my tool ThoughtLoom to prototype and evaluate various schemes of prompts and supplied context to achieve success on tasks.
Emerging LLM architecture
If you really want to start exploiting the power of LLMs in your initiative, it only takes turning on access to an LLM and starting with some prompts against local files. Scaling up and running with LLMs to realize value written in this article will depend on a more robust system of components.
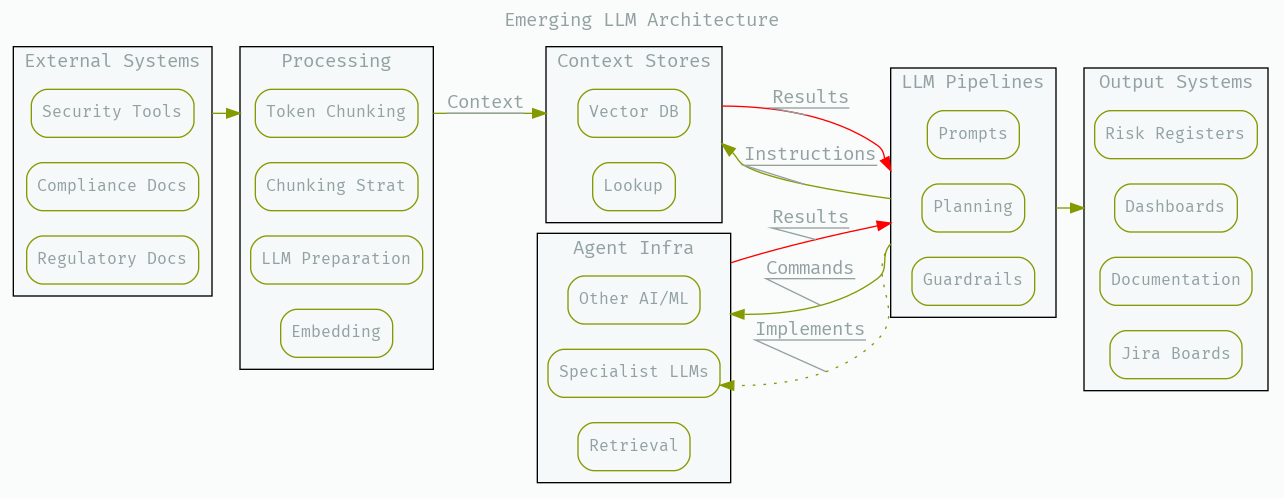
Let’s say you want to ask LLM questions about a repository of code, here are three approaches that essentially do the same things; consume a repository, chunk its content, generate embeddings, store them in a vector database, and use k-nearest-neighbors to select the right elements of context for a given query;
Via Azure: Semantic Kernel Embeddings and Memories: Explore GitHub Repos with Chat UI
Open Source; peterw/Chat-with-Github-Repo
Or Tutorial; The Ultimate Guide to Chatting with ANY GitHub Repository using OpenAI LLMs and LangChain
Today, individuals are using an expansive set of open-source libraries like LangChain and LlamaIndex along with embedding-lookup friendly vector databases like pinecone, to solve one-off problems, and startups and incumbent cloud vendors are working on enterprise-friendly solutions. You will probably want to start running mini-experiments using similar tools, and then begin scaling up with some common architecture;
Context Stores;
You will want to provide easy access to context enrichment for in-prompt context;
Over coding and security policy documents, regulatory and compliance documents, in-house repositories, runtime telemetry, and inventory.
Partially this might be a vector database with embeddings, and it might also include lookup tables for fixed instructions, like code-fix-policies.
Agent Infrastructures;
An environment to create and expose agents to LLMs for tasking and response. You will want to invoke a specialist LLM from another LLM, you may want to expose a menu of AI/ML models for it to use, look up relevant internal coding policies, or you might want it to fetch information about the environment.
LLM Pipelines;
An environment to layer LLM prompts and manage centralized access to APIs or in-house models. These have to provide access to all the best tooling to make it user-friendly, efficient, and safe to work with LLMs - exposing content stores and agents as necessary.
These systems are the place to add support for LLM-performance enhancing building blocks like Tree of Thoughts and Voyager - as well as laying in defensive techniques like NeMo Guardrails, Langchain Guardrails, and Microsoft Guidance - malicious prompt embedding distances, user-input preprocessing and maliciousness scoring - and the stream of techniques that will follow in years and months to come.
To me, it seems obvious that these technologies will become an indispensable part of any security platform. You’ll want to feed in information from your mesh of tooling and adjust tooling to expose context back to the LLMs. You want to expose specialist LLM or AI/ML models as agents for specific tasks. You will have to develop methods that allow the results to be imported into risk registers, dashboards, and other interfaces to your initiative. How much you run yourself or outsource to others will be up to you.
These architectures may become as big as the ETL and SOA movements they rhyme with.
Of course, just having access to the technology isn’t enough, we all have to find the limits of the technology when applied to software security problems, and the most performant methods of generating value from them.
Leaning in with LLMs
Organizations with innovative security engineering teams are already leaning into LLMs and internally realizing many of these value propositions, application security companies are in a rush to improve their products with LLMs, or at least make their interfaces less horrible to work with by adding chat interfaces to their products. I’ve seen first-hand some of the innovation going on at firms large and small, as well as discussed many of the applications outlined here with folks managing initiatives and doing security engineering work.
As an industry (society?), we’re going to spend a lot of time discovering the best ways to use LLMs to make everyone more productive. As we move forward, some jobs will become obsolete - writing patches, running a tool, and writing a report. The people who bring insight and perspective to these types of tasks will learn how to work side-by-side with LLMs to achieve unprecedented scale, depth, and useful insight.
Our security programs will start being able to scale a philosophy of operation with consistency across an organization. Tribes won’t be ad-hoc any more. Maybe we’ll be able to objectively measure the results of different prompt packs, and switch them out at will one day? Perhaps booting an initiative might be as easy as forking a repo of templates and loading them into your security platform.
We will need to identify and foster components that can form pipelines that are open and flexible, and can be used by non-experts to improve or innovate using these technologies.
And we’ll need a huge corpus of ‘prompts’ and ‘context’ that get LLMs reliably into a space where they are maximally useful to whatever the task is.