Automating Core AppSec Tooling Dev Loops: Language Model Powered Rule Generation
Shortening the time to live from weeks to hours for gaps in AppSec tooling rules and checker coverage.
Travis dropped
This technical article explores in depth one way to layer embeddings powered k-nearest-neighbor (kNN) search, retrieval augmented generation, and specialist LLM tools to turn what might take a single engineer a month to complete into a task that completes in 40 minutes and costs less than $10 in OpenAI API credits.
If you’ve followed my previous work on where innovators can employ LLMs to solve tough AppSec challenges - you know that one important area is closing the time from discovery of an issue to the production of rules that flexible, powerful, (and often open source) automated tools can use to identify those issues at scale. Thousands of engineers contributing to commercial and open-source projects dedicate dozens of hours each to producing these artifacts in response to disclosures. Here I’ll show you how to compose a system of LLM tools that will help those same folks do more in an order of magnitude less time, at an order of magnitude less cost, for orders of magnitude more value delivered to society.
This article is focused on exploring the technical design, ordering, and composition of discrete tasks that can be applied to this class of problem, it’s not a thought piece, it’s a practical guide. If you just want to skip to the code, you can do so by taking a look at the example I’ve published in the ThoughtLoom repository.
The future is here - it’s just not evenly distributed.
Here I explore a Proof of Concept that demonstrates how to examine the open source project PyTM’s threat rule-set for gaps against the latest version of MITREs CAPEC database, generate PyTM rules, and provide positive and negative examples demonstrating each threat.
Approach
PyTM ships with a default set of rules that evaluate a given threat model for applicable threats, the individual threat rules are JSON documents that contain information developers can use to address those threats, as well as predicate conditions (as evaluated python statements) that the tooling uses to recognize them. As our collective knowledge about threats evolves, and new technologies and platforms introduce new threats, this database runs out of date with the latest in defensive knowledge. Aside from employing several dozen engineers who are versed in PyTM and are tasked with keeping abreast of these developments - one clear solution is to employ LLMs to determine gaps in coverage, create the first draft of rules that will cover identified gaps, and finally emit positive and negative examples that demonstrate the rules.
In order to help the LLM deliver value given its constraints in context length, tendency to invent (or hallucinate) information, and limitations in the complexity it can express in a single pass we will break the task into several steps;
- Recognize gaps versus an inventory of threats. In this case, we’ll walk each issue that appears in MITRE’s CAPEC against the most relevant threats in PyTM’s rule-set,
- Generate a candidate PyTM rule for the identified gap, and finally
- Generate positive and negative PyTM model examples that demonstrate the new finding.
To help the LLM in its mission, we’ll produce a set of embeddings over the existing PyTM rule-set, and then present those rules which most clearly match the candidate CAPEC entry - and continue to pass through these results along the execution of 3 specialist LLM tools.
Implementation
Here we will walk through the three high level phases, showing intermediate steps and exploring the design of our specialist LLM tools.
Step 1: Generation, kNN retrieval, and LLM query enhancement with embeddings
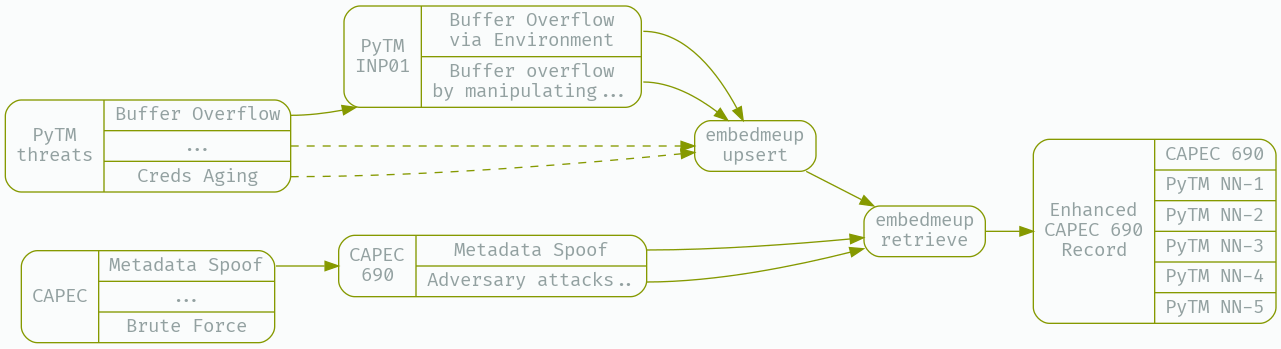
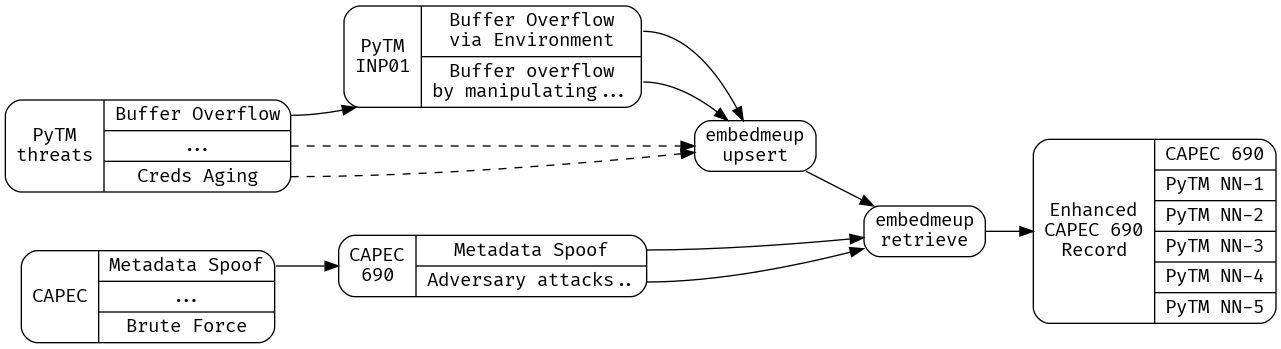
First, we’ll prepare our working data, the latest CAPEC entries, and the most-up-to-date version of PyTM’s built in threat library.
wget https://capec.mitre.org/data/xml/capec_latest.xml -O _work/capec_latest.xml
wget https://raw.githubusercontent.com/izar/pytm/master/pytm/threatlib/threats.json -O _work/threats.json
What we need to do to minimize our use of the precious context window - as well as avoid overwhelming the LLM with irrelevant information - is develop a strategy for surfacing the closest existing PyTM rules to a given CAPEC entry. A good strategy is to prepare embeddings for the existing PyTM rules, then perform kNN search based on the embedding distance of a CAPEC entry from those existing rules.
Here I’ll use my open source CLI tool embedmeup to prepare a fresh namespace to contain all of the existing PyTM rules;
embedmeup -index="$p_index" -region="$p_region" -project "$p_project" -namespace "$p_namespace" -mode deleteAll
Next, we’ll prepare a field from the existing PyTM rules that contains enough information to generate a good match to a given CAPEC issue - I’m using jq here to add a new string object to each rule, called ‘embedding’, and then I instruct embedmeup to calculate an embedding over that field, and store it in pinecone;
jq '.[] | .+ {embedding: (.description + " " + .details)}' _work/threats.json | embedmeup -index="$p_index" -region="$p_region" -project "$p_project" -namespace "$p_namespace" -mode upsert -param embedding
A sample embedded threat looks like this;
{
"SID": "AC22",
"target": ["Dataflow"],
"description": "Credentials Aging",
"details": "If no mechanism is in place for managing credentials (passwords and certificates) aging, users will have no incentive to update passwords or rotate certificates in a timely manner. Allowing password aging to occur unchecked or long certificate expiration dates can result in the possibility of diminished password integrity.",
"Likelihood Of Attack": "Medium",
"severity": "High",
"prerequisites": "",
"condition": "any(d.isCredentials for d in target.data) and target.sink.inScope and any(d.credentialsLife in (Lifetime.UNKNOWN, Lifetime.LONG, Lifetime.MANUAL, Lifetime.HARDCODED) for d in target.data)",
"mitigations": "All passwords and other credentials should have a relatively short expiration date with a possibility to be revoked immediately under special circumstances.",
"example": "",
"references": "https://cwe.mitre.org/data/definitions/262.html, https://cwe.mitre.org/data/definitions/263.html, https://cwe.mitre.org/data/definitions/798.html",
"embedding": "Credentials Aging If no mechanism is in place for managing credentials (passwords and certificates) aging, users will have no incentive to update passwords or rotate certificates in a timely manner. Allowing password aging to occur unchecked or long certificate expiration dates can result in the possibility of diminished password integrity."
}
With the upserts completed, we can now use kNN search over embeddings to find those PyTM issues that are closest to a CAPEC issue - we will use xq-python, part of the yq package on debian, to transform XML into JSON - filter out CAPEC entries that are Deprecated, and collapse complex Description fields (which can contain xhtml entities) into simple strings. After preparing the CAPEC dataset as JSON that can be consumed by embedmeup and other downstream tools, we look for the 5 closest embeddings to a given CAPEC entry, the 5 closest PyTM threat rules, and cache the results in CAPEC_Enhanced.json.
xq-python -r '.["Attack_Pattern_Catalog"]["Attack_Patterns"]["Attack_Pattern"][] | select(."@Status" != "Deprecated")' _work/capec_latest.xml | jq '.Description |= (if type == "string" then . else tostring end)| . + {embedding:("# Name: " + .["@Name"]+"\n"+.Description)}' | embedmeup -index="$p_index" -region="$p_region" -project "$p_project" -namespace "$p_namespace" -mode retrieve -topK 5 -param embedding | tee _work/CAPEC_Enhanced.json | jq
We can see the embeddings enhanced CAPEC entries look like this;
{
"Input": {
"@Abstraction": "Detailed",
"@ID": "95",
"@Name": "WSDL Scanning",
"@Status": "Draft",
//...
"Description": "This attack targets the WSDL interface made available by a web service. The attacker may scan the WSDL interface to reveal sensitive information about invocation patterns, underlying technology implementations and associated vulnerabilities. This type of probing is carried out to perform more serious attacks (e.g. parameter tampering, malicious content injection, command injection, etc.). WSDL files provide detailed information about the services ports and bindings available to consumers. For instance, the attacker can submit special characters or malicious content to the Web service and can cause a denial of service condition or illegal access to database records. In addition, the attacker may try to guess other private methods by using the information provided in the WSDL files.",
"Example_Instances": {
//...
},
//...
"Typical_Severity": "High",
"embedding": "# Name: WSDL Scanning\nThis attack targets the WSDL interface made available by a web service. The attacker may scan the WSDL interface to reveal sensitive information about invocation patterns, underlying technology implementations and associated vulnerabilities. This type of probing is carried out to perform more serious attacks (e.g. parameter tampering, malicious content injection, command injection, etc.). WSDL files provide detailed information about the services ports and bindings available to consumers. For instance, the attacker can submit special characters or malicious content to the Web service and can cause a denial of service condition or illegal access to database records. In addition, the attacker may try to guess other private methods by using the information provided in the WSDL files."
},
"Response": [
{
"Likelihood Of Attack": "High",
"SID": "INP32",
"condition": "target.controls.validatesInput is False or target.controls.sanitizesInput is False or target.controls.encodesOutput is False",
"description": "...",
"details": "...",
"embedding": "XML Injection An attacker utilizes crafted XML user-controllable input to probe, attack, and inject data into the XML database, using techniques similar to SQL injection. The user-controllable input can allow for unauthorized viewing of data, bypassing authentication or the front-end application for direct XML database access, and possibly altering database information.",
"example": "....",
"mitigations": "....",
"prerequisites": "...",
"references": "https://capec.mitre.org/data/definitions/250.html",
"severity": "High",
"target": ["Process"]
}
//... 4 more ...
]
}
Now that we have a collection of CAPEC entries under ‘Input’ with retrieved PyTM rules under ‘Response’ we are free to use an LLM to disposition a candidate CAPEC entry against the closest 5 PyTM rules. We’ll determine whether a given CAPEC entry deserves its very own PyTM rule in this step.
Aside from actually achieving success in using LLMs for non-trivial workflows this chunking of tasks allows us to use lower-cost models for less difficult or complicated tasks, for the first task we can rely on the low cost OpenAI GPT-3.5-Turbo model.
Here I’ll define a configuration, system prompt, and user prompt that my open source tool ThoughtLoom can use to provide that disposition.
What we want here is a clear and structured disposition of whether a threat should be generated, what we’ll use is OpenAI Chat API’s function support to get well formatted work as JSON objects out of the model. ThoughtLoom supports this functions API, and will validate emitted calls against the provided JSONSchema doc. The trick we’ll employ here is to tell the model to ‘insert threats into the database’, using our ‘insert’ function.
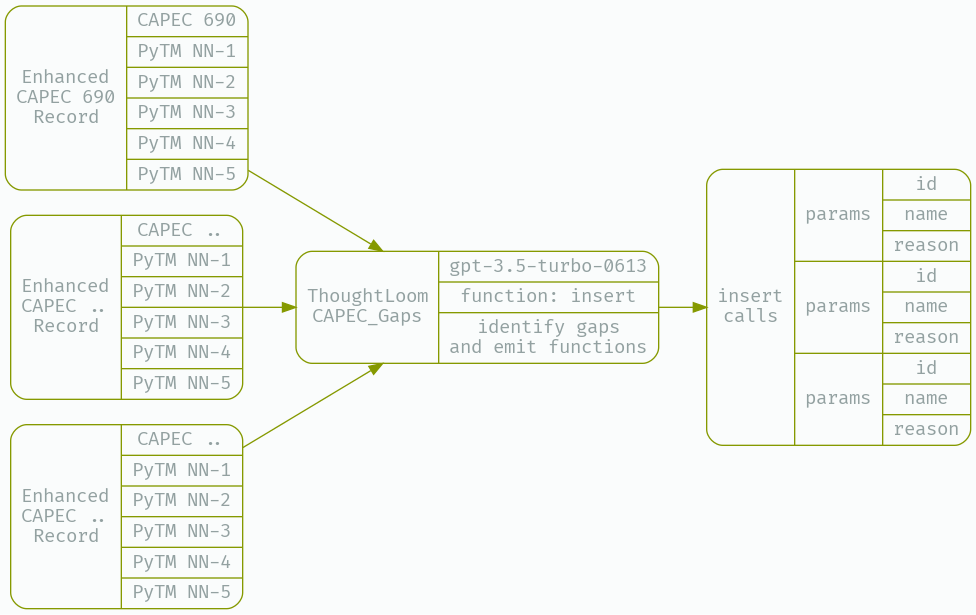
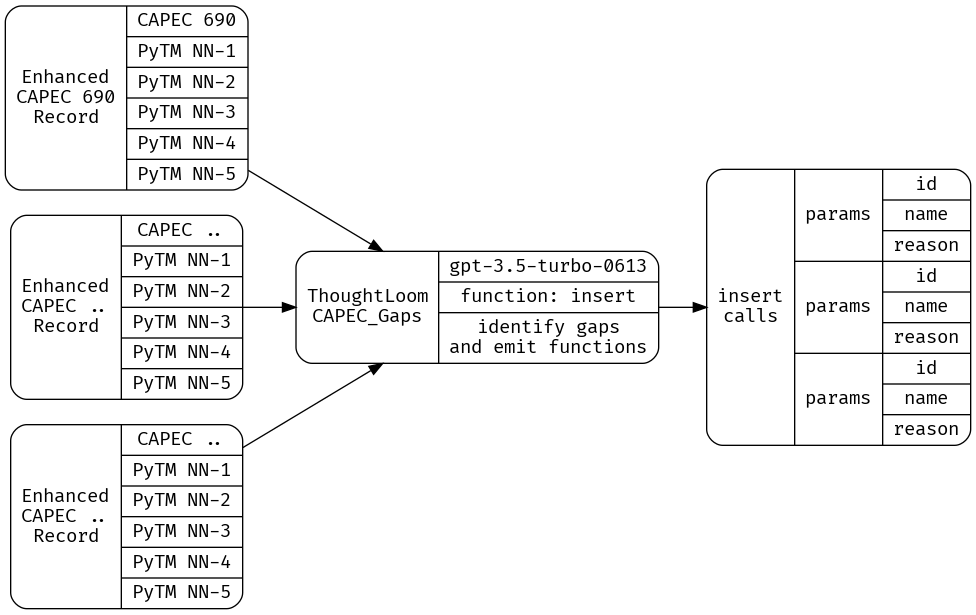
We’ll define our new tool under CAPEC_Gaps, using the following configuration, simple.toml;
template_system = "./system.tmpl"
template_user = "./user.tmpl"
max_tokens = 1000
model = "gpt-3.5-turbo-0613"
temperature = 0.5
[[functions]]
name = "insert"
description = "Flag a threat for insertion"
parameters = '''
{
"type": "object",
"required": [
"id",
"name",
"reason"
],
"properties": {
"id": {
"type": "string",
"description": "The threat ID."
},
"name": {
"type": "string",
"description": "The name of the threat."
},
"reason": {
"type": "string",
"description": "Why the threat must be added."
}
}
}
'''
Here we’re using gpt-3.5-turbo-0613, as it supports function calls, we’ll use a lower-than-default temperature to keep the model more or less on the rails, and we specify a JSONSpec for the ‘insert’ function that we expect results in.
Our system template will introduce the problem and kNN retrieved context that it needs to do its job;
You identify whether there is a significant reason to update an inventory of threats based on a provided threat name and description. Insert gaps into the database where there is a strong reason to add a new item to the threat database. If there is no reason to update the database respond with 'OK'.
## Existing Threat Database
{{range $val := .Response}}
### Threat: {{$val.description}}
{{$val.details}}
{{$val.example}}
{{end}}
We’re clearly instructing the model to only call ‘insert’ when it identifies a gap between the existing database of threats and the user-provided CAPEC entry. Our user template is just as simple;
### Threat
## ID {{ index .Input "@ID"}}
## NAME {{ index .Input "@Name"}}
{{.Input.Description}}
Finally, let’s have ThreatLoom call OpenAI to do the work and see what we get;
cat _work/CAPEC_Enhanced.json | thoughtloom -c ./CAPEC_Gaps/simple.toml -p 10 | tee _work/CAPEC_Run.json | jq
Querying for function calls with cat _work/CAPEC_Run.json| jq -r '(select(.finish_reason=="function_call"))|.function_params' We get a set of entries (can vary from 8-12 or more, run to run);
{
"id": "74",
"name": "Manipulating State",
"reason": "Describes a significant risk of manipulating state information in software applications and hardware systems, which can lead to various security vulnerabilities and potential attacks."
}
//...
{
"id": "85",
"name": "AJAX Footprinting",
"reason": "This threat describes a specific attack that takes advantage of the frequent client-server roundtrips in Ajax conversations to scan a system. It highlights the optimization of existing vulnerabilities and the ability to enumerate and gather information about the target environment. This threat provides valuable insight into the potential vulnerabilities and can be used to support other attacks, such as XSS."
}
Step 2: Generate PyTM rules for each gap
We need to generate valid PyTM rules, which rely on complex predicate statements that satisfy properties that are part of PyTM internals. Our focus now is to provide the model with all the information it needs to generate these predicate statements in a way that is rational and idiomatic to the PyTM project. Our PoC approach here is naive - we could use embeddings to save on context, but the volume of work is low, and pricing is low enough that we can just pass those internals statically in the system prompt.
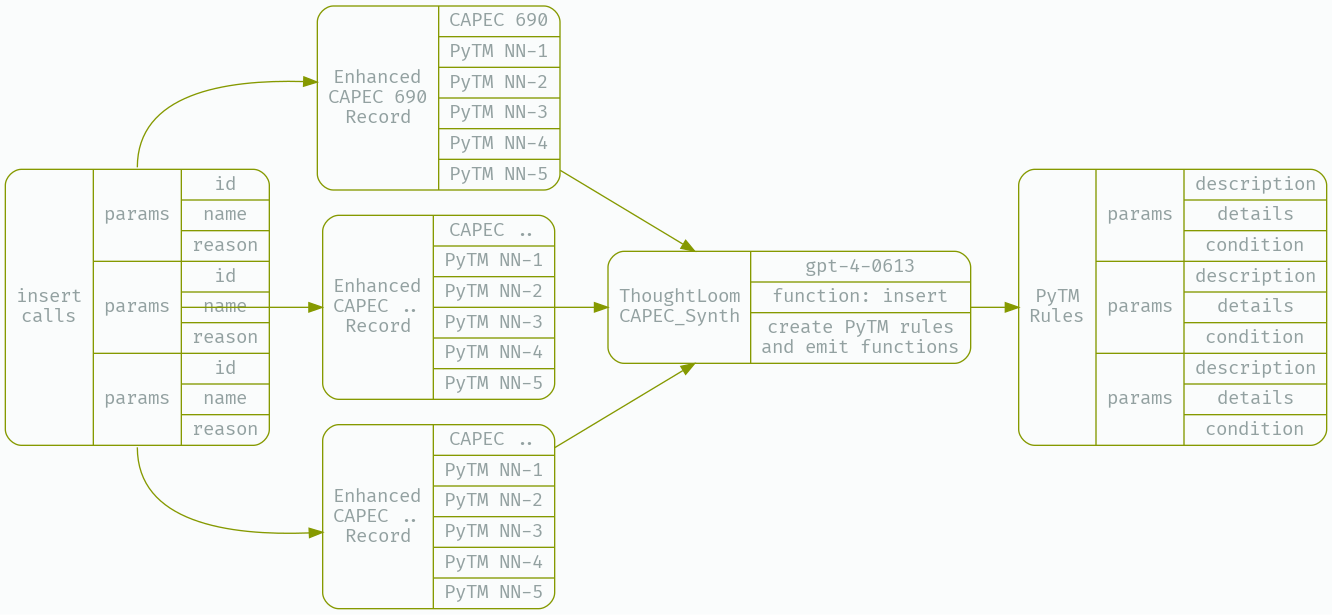
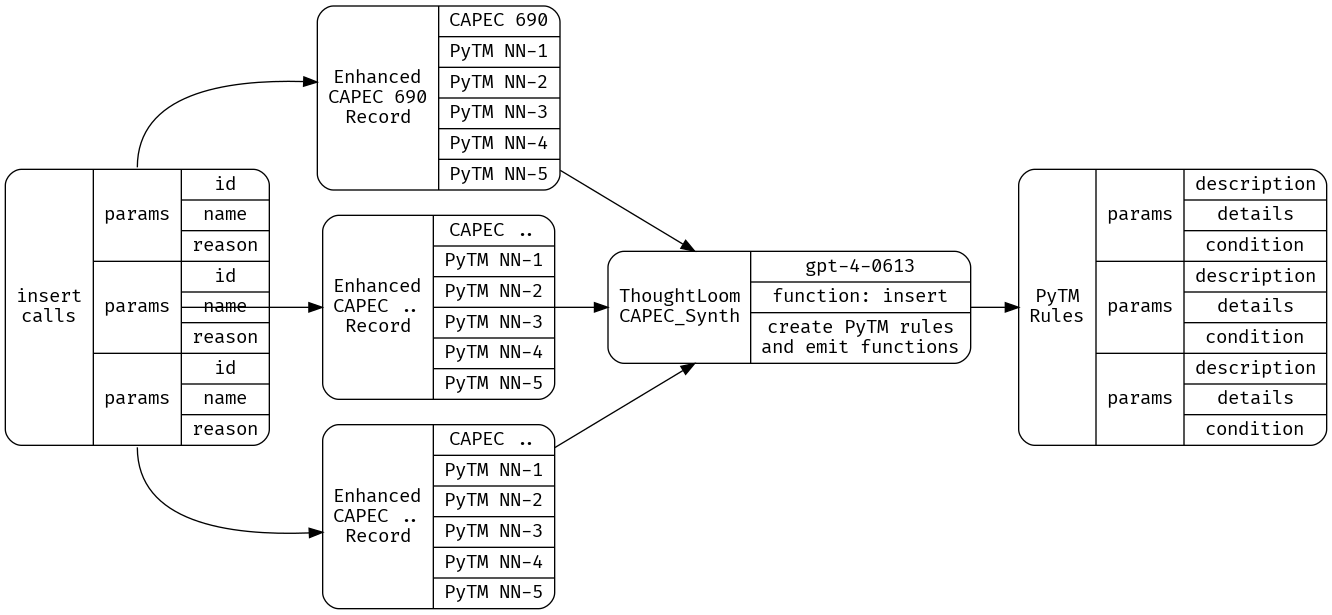
As before, we will prepare a new LLM tool under CAPEC_Synth - its job will be to make function calls containing well formed PyTM rules given the new rule under consideration. Our configuration file provides the JSONSchema function spec and other setup;
template_system = "./system.tmpl"
template_user = "./user.tmpl"
max_tokens = 1500
model = "gpt-4-0613"
temperature = 0.5
[[functions]]
name = "insert"
description = "Insert a new threat"
parameters = '''
{
"type": "object",
"properties": {
"Likelihood Of Attack": {
"type": "string",
"description": "How likely an attacker is to exploit this weakness.",
"enum": [
"Low",
"Medium",
"High",
"Very High"
]
},
"condition": {
"type": "string",
"description": "A string of conditions which trigger the threat, is evaluated as a python statement returning true or false."
},
"newConditions" : {
"type": "string",
"description": "Optional - describes new properties or conditions that must be added to support a good predicate condition statement."
},
"description": {
"type": "string",
"description": "A short name for this threat."
},
"details": {
"type": "string",
"description": "A short description of the threat."
},
"example": {
"type": "string",
"description": "An example of how an actor leverages the threat."
},
"mitigations": {
"type": "string",
"description": "Generically, how an engineer can address the threat."
},
"prerequisites": {
"type": "string",
"description": "The conditions for the threat."
},
"references": {
"type": "string",
"description": "A set of URLs to CWE, or CAPEC websites describing the threat."
},
"severity": {
"type": "string",
"description": "The impact of the threat.",
"enum": [
"Low",
"Medium",
"High",
"Very High"
]
},
"target": {
"type": "array",
"items": {
"type": "string",
"enum": [
"Process",
"Server",
"Datastore",
"Lambda",
"ExternalEntity",
"Dataflow"
]
}
}
},
"required": [
"Likelihood Of Attack",
"condition",
"description",
"details",
"example",
"mitigations",
"prerequisites",
"references",
"severity",
"target"
]
}
Now we’ll pass in all the PyTM internals that the LLM will need to generate quality candidate rules in the system prompt, as well as the nearest PyTM rule examples we were able to find via kNN search;
Create a new entry for the threat database and insert it. Several examples follow that show well-formed entries.
Condition statements are python boolean predicate statements, evaluated over several target properties.
## A target has properties; e.g. (target.protocol == 'HTTP' and target.usesSessionTokens is True)
class Process(Asset):
"""An entity processing data"""
codeType = varString("Unmanaged")
implementsCommunicationProtocol = varBool(False)
tracksExecutionFlow = varBool(False)
implementsAPI = varBool(False)
environment = varString("")
allowsClientSideScripting = varBool(False)
…
processedBy = varElements([], doc="Elements that store/process this piece of data")
def hasDataLeaks(self):
return any(
d.classification > self.source.maxClassification
or d.classification > self.sink.maxClassification
or d.classification > self.maxClassification
for d in self.data
)
## Examples
{{range $val := .identifier.Response}}
### Example
"Likelihood Of Attack" {{index $val "Likelihood Of Attack"}}
"condition" {{$val.condition}}
"description" {{$val.description}}
"details" {{$val.details}}
"example" {{$val.example}}
"mitigations" {{$val.mitigations}}
"prerequisites" {{$val.prerequisites}}
"references" {{$val.references}}
"severity" {{$val.severity}}
"target" [
{{range $sev := $val.target}}{{$sev}}{{end}}
]
{{end}}
Our user template will simply pass in details from the identified CAPEC entry directly;
### Threat
## ID: {{ index .identifier.Input "@ID"}}
## NAME: {{ index .identifier.Input "@Name"}}
## Likelihood: {{.identifier.Input.Likelihood_Of_Attack}}
## Severity: {{.identifier.Input.Typical_Severity}}
## Description
{{.identifier.Input.Description}}
## Mitigations
{{.identifier.Input.Mitigations}}
## Prerequisite
{{.identifier.Input.Prerequisites}}
## Related Weaknesses
{{.identifier.Input.Related_Weaknesses}}
Finally, let’s prepare the input objects from the previous step and pass them to ThoughtLoom for execution on OpenAI endpoints. Here we’re going to re-inflate the ‘identifier’ parameter, as it contains the original input with the embeddings and full CAPEC objects.
jq -n 'inputs | select(.finish_reason == "function_call") | .function_params |= fromjson | .identifier |= fromjson' _work/CAPEC_Run.json | thoughtloom -c ./CAPEC_Synth/simple.toml | tee _work/CAPEC_Synth.json | jq
GPT-4’s ability to use chunks of Python code directly from the PyTM project, and extrapolate how to form predicates based on provided examples is truly impressive. For our PoC purposes, this is sufficient - however there are significant gains to be had in splitting this step in two - a planning step and an execution step, as well as incorporating ensemble ranking methods.
Let’s take a look at what we get with cat _work/CAPEC_Synth.json| jq -r '(select(.finish_reason=="function_call"))|.function_params'| jq.
{
"Likelihood Of Attack": "High",
"condition": "target.controls.validatesInput is False or target.controls.sanitizesInput is False or target.controls.hasAccessControl is False",
"description": "AJAX Footprinting",
"details": "This attack utilizes the frequent client-server roundtrips in Ajax conversation to scan a system. While Ajax does not open up new vulnerabilities per se, it does optimize them from an attacker point of view. A common first step for an attacker is to footprint the target environment to understand what attacks will work. Since footprinting relies on enumeration, the conversational pattern of rapid, multiple requests and responses that are typical in Ajax applications enable an attacker to look for many vulnerabilities, well-known ports, network locations and so on. The knowledge gained through Ajax fingerprinting can be used to support other attacks, such as XSS.",
"example": "While a user is logged into his bank account, an attacker can send an email with some potentially interesting content and require the user to click on a link in the email. The link points to or contains an attacker setup script, probably even within an iFrame, that mimics an actual user form submission to perform a malicious activity, such as transferring funds from the victim's account. The attacker can have the script embedded in, or targeted by, the link perform any arbitrary action as the authenticated user. When this script is executed, the targeted application authenticates and accepts the actions based on the victims existing session cookie.",
"mitigations": "Design: Use browser technologies that do not allow client side scripting. Implementation: Perform input validation for all remote content.",
"prerequisites": "The user must allow JavaScript to execute in their browser",
"references": "https://capec.mitre.org/data/definitions/169.html, http://cwe.mitre.org/data/definitions/200.html",
"severity": "Low",
"target": [
"Server"
]
}
//...
{
"Likelihood Of Attack": "High",
"condition": "target.controls.validatesInput is False or target.controls.sanitizesInput is False",
"description": "Using Slashes and URL Encoding Combined to Bypass Validation Logic",
"details": "This attack targets the encoding of the URL combined with the encoding of the slash characters. An attacker can take advantage of the multiple ways of encoding a URL and abuse the interpretation of the URL. A URL may contain special character that need special syntax handling in order to be interpreted. Special characters are represented using a percentage character followed by two digits representing the octet code of the original character (%HEX-CODE). For instance US-ASCII space character would be represented with %20. This is often referred as escaped ending or percent-encoding. Since the server decodes the URL from the requests, it may restrict the access to some URL paths by validating and filtering out the URL requests it received. An attacker will try to craft an URL with a sequence of special characters which once interpreted by the server will be equivalent to a forbidden URL. It can be difficult to protect against this attack since the URL can contain other format of encoding such as UTF-8 encoding, Unicode-encoding, etc.",
"example": "An attacker crafts an URL with a sequence of special characters which once interpreted by the server is equivalent to a forbidden URL. The server, which decodes the URL from the requests, may restrict the access to some URL paths by validating and filtering out the URL requests it received.",
"mitigations": "Assume all input is malicious. Create an allowlist that defines all valid input to the software system based on the requirements specifications. Input that does not match against the allowlist should not be permitted to enter into the system. Test your decoding process against malicious input. Be aware of the threat of alternative method of data encoding and obfuscation technique such as IP address encoding. When client input is required from web-based forms, avoid using the 'GET' method to submit data, as the method causes the form data to be appended to the URL and is easily manipulated. Instead, use the 'POST' method whenever possible. Any security checks should occur after the data has been decoded and validated as correct data format. Do not repeat decoding process, if bad character are left after decoding process, treat the data as suspicious, and fail the validation process. Refer to the RFCs to safely decode URL. Regular expression can be used to match safe URL patterns. However, that may discard valid URL requests if the regular expression is too restrictive. There are tools to scan HTTP requests to the server for valid URL such as URLScan from Microsoft (http://www.microsoft.com/technet/security/tools/urlscan.mspx).",
"prerequisites": "The target application must accept a string as user input, fail to sanitize characters that have a special meaning in the parameter encoding, and insert the user-supplied string in an encoding which is then processed.",
"references": "https://capec.mitre.org/data/definitions/173.html, http://cwe.mitre.org/data/definitions/177.html, http://cwe.mitre.org/data/definitions/707.html, http://cwe.mitre.org/data/definitions/697.html, http://cwe.mitre.org/data/definitions/74.html, http://cwe.mitre.org/data/definitions/22.html, http://cwe.mitre.org/data/definitions/73.html, http://cwe.mitre.org/data/definitions/172.html, http://cwe.mitre.org/data/definitions/20.html",
"severity": "High",
"target": [
"Server"
]
}
We can see that it has generated reference URLs inferring from issue IDs passed in from the CAPEC listing. These are almost always correct - but should be validated. Severities, targets, and so on are often not exactly perfect - and a couple of them are bogus. For me, these are areas of improvement for ensemble methods - but the PoC performance is solid enough that it obviously provides unprecedented value for human-in-the-loop processes.
Next, we generate positive and negative examples that demonstrate how functional these generated rules are out of the box.
Step 3: Generate demonstrative positive and negative examples for the new rules
When developing new rules it’s common practice to provide positive and negative examples that demonstrate that they work. Along with recognizing a coverage gap and actually writing the rules this is essential and mostly manual labor today that we hope to address by using LLMs.
And that means we need our third and final LLM tool, Synth_pos_neg.
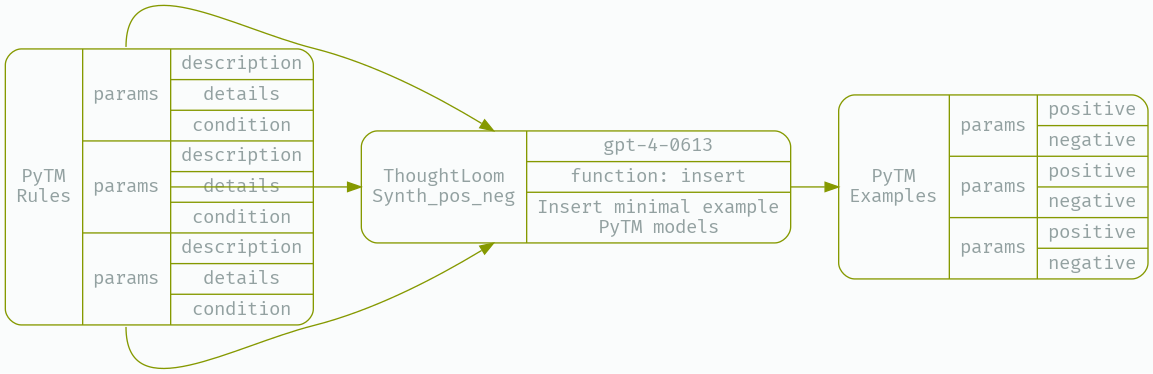
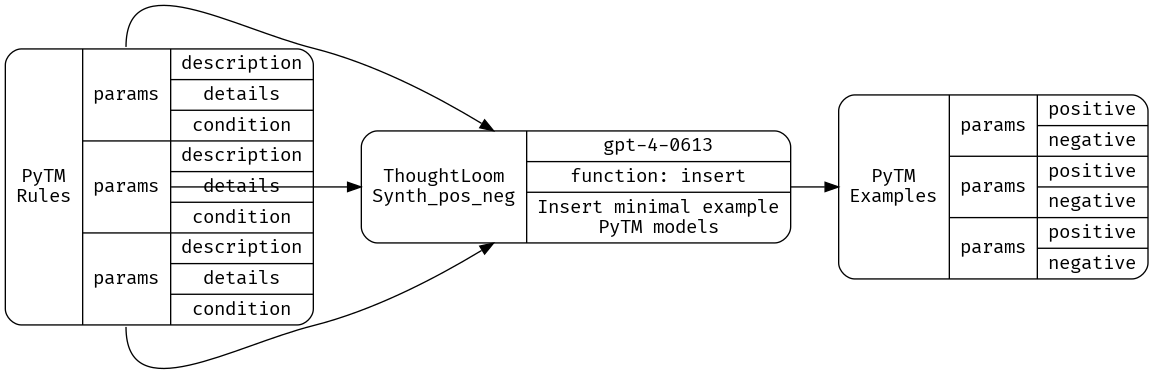
Again, our configuration file will specify a function spec to emit into, a reliance on GPT-4, and some tuning of temperature and token generation penalties to achieve acceptable performance. Currently the LLM has a hard time remembering to escape newlines in generated code - after all there’s a lot of nested escaping going on with code - here we’ll remind the model to do this escaping several times, but perhaps this is another target for splitting into two or more LLM tools.
template_system = "./system.tmpl"
template_user = "./user.tmpl"
max_tokens = 2500
model = "gpt-4-0613"
temperature = 0.5
presence_penalty = 0.1
frequency_penalty = 0.1
[[functions]]
name = "insert"
description = "Insert positive and negative examples into the database."
parameters = '''
{
"type": "object",
"properties": {
"positive": {
"type": "string",
"description": "An escaped PyTM example showing the positive example."
},
"negative": {
"type": "string",
"description": "An escaped PyTM example showing the negative example."
}
},
"required": [
"positive",
"negative"
]
}
'''
Since we are now generating PyTM models our system prompt again needs to provide the model with all of the relevant internal documentation. Again, we could use embeddings here to save on context window - but it was unnecessary for this PoC. Here I needed to simplify the documentation of PyTM’s internals significantly to keep the model from getting off topic and… generating PyTM internal code.
Insert minimal example PyTM models that demonstrate a positive example - where the rule is triggered - and a negative example - where the threat is eliminated. Positive and negative examples must contain the minimum number of elements to demonstrate just the rule that the user provides. Don't respond to the user, only insert the examples into the database.
### PyTM Internals
Condition statements are python boolean predicate statements, evaluated over several target properties.
## Target Types;
Process:
#An entity processing data
string codeType
bool implementsCommunicationProtocol
…
## Controls are accessed on each element using target.controls - they are not imported.
controls:
#Controls implemented by/on and Element
bool authenticatesDestination
bool authenticatesSource
…
## Enum Values
Classification:
Enum UNKNOWN, PUBLIC, RESTRICTED, SENSITIVE, SECRET, TOP_SECRET
Lifetime:
Enum NONE, UNKNOWN, SHORT_LIVED, LONG_LIVED, AUTO_REVOKABLE, MANUALLY_REVOKABLE, HARDCODED
DatastoreType:
Enum UNKNOWN, FILE_SYSTEM, SQL, LDAP, AWS_S3
TLSVersion:
Enum NONE, SSLv1, SSLv2, SSLv3, TLSv10, TLSv11, TLSv12, TLSv13
### Example PyTM Model
#!/usr/bin/env python3
from pytm import (
TM,
Actor,
Boundary,
Classification,
Process,
Data,
Dataflow,
Datastore,
Lambda,
Server,
DatastoreType,
)
tm = TM("Example TM")
tm.isOrdered = True
tm.mergeResponses = True
internet = Boundary("Internet")
...
if __name__ == "__main__":
tm.process()
Insert minimal example PyTM models that demonstrate a positive example - where the rule is triggered - and a negative example - where the threat is eliminated. Positive and negative examples must contain the minimum number of elements to demonstrate just the rule that the user provides. Don't respond to the user, only insert the examples into the database. Remember to escape newlines and other characters in the function call.
You will note I’ve repeated the task prompt, as well as instruction to properly escape the function call - ‘recency bias’. These were essential tweaks that became apparent after many evaluation runs.
The user template will just present the rule’s contents to the LLM;
"Likelihood Of Attack" {{index . "Likelihood Of Attack"}}
"description" {{.description}}
"details" {{.details}}
"example" {{.example}}
"references" {{.references}}
"severity" {{.severity}}
"mitigations" {{.mitigations}}
"prerequisites" {{.prerequisites}}
"condition" {{.condition}}
## Condition can only be triggered on an instance of these pytm classes.
"target" [
{{range $sev := .target}}{{$sev}}{{end}}
]
Finally we’ll present our newly minted rules for positive/negative example generation to ThoughtLoom;
jq -r .function_params _work/CAPEC_Synth.json | thoughtloom -c ./Synth_pos_neg/simple.toml | tee _work/posneg.json | jq
We will post-process the results and populate a check-specific directory with positive/negative examples, and the candidate threat;
jq 'select(.finish_reason == "function_call") | .function_params = (.function_params | fromjson) + {input: .identifier| fromjson} | .function_params' _work/posneg.json | jq -c -s '.[]' | while read -r line; do
description=$(printf '%s' "$line" | jq -r '.input.description')
description=$(echo "$description" | tr -dc '[:alnum:]\n\r' | tr '[:upper:]' '[:lower:]')
description="_work/ex_$description"
mkdir -p "$description"
printf '%s' "$line" | jq -r '.positive' > "${description}/positive.py"
printf '%s' "$line" | jq -r '.negative' > "${description}/negative.py"
printf '%s' "$line" | jq '.input | .+ {SID:"TEST"} | [.]' > "${description}/threats.json"
sed -i '/\(\s*[a-zA-Z_][a-zA-Z0-9_]*\)\.process()/ s//\1.threatsFile = ".\/threats.json"\n\1.process()/g' "${description}/positive.py"
sed -i '/\(\s*[a-zA-Z_][a-zA-Z0-9_]*\)\.process()/ s//\1.threatsFile = ".\/threats.json"\n\1.process()/g' "${description}/negative.py"
done
We can see PyTM models generated like;
cat positive.py
#!/usr/bin/env python3
from pytm import (
TM,
Actor,
Boundary,
Classification,
Process,
Data,
Dataflow,
Datastore,
Lambda,
Server,
DatastoreType,
)
tm = TM("Example TM")
tm.isOrdered = True
tm.mergeResponses = True
proc = Process("A process")
proc.codeType="C"
proc.implementsAPI = True
proc.controls.authenticatesSource = False
if __name__ == "__main__":
tm.threatsFile = "./threats.json"
tm.process()
To test them you can python -m pip install pytm and navigate to each directory;
python positive.py --report ../pytm/docs/advanced_template.md
And see the TEST threat;
**Threats**
<details>
<summary>1 -- TEST -- Action Spoofing</summary>
</details>
And that the negative example doesn’t flag;
python negative.py --report ../pytm/docs/advanced_template.md
Improving performance
You might note that ‘8-12’ gaps seems on the low side, after all - there’s 103 existing PyTM rules and (at the time of writing this article) 559 CAPEC issues under consideration. 8-12 was a convenient answer in the first step for prototyping the later phases, but now that we have acceptable results end to end, let’s make some improvements.
Gap recognition
The first place I looked for improving this tool was reducing the ‘perplexity’ measured over that prompt. The simplest description of perplexity is ‘how surprising the text is’ (as measured over token probabilities) to an LLM. Working from https://github.com/stjordanis/betterprompt/ and checking https://arxiv.org/pdf/2212.04037.pdf it looks clear that low perplexity in a prompt results in better model performance.
I prepared a few prompts working from the author’s suggestion to have GPT generate a few variants, and making some edits based on the results - those final measures are below, with my original prompt marked with **;
Prompt: You identify whether there is a significant reason to update an inventory of threats based on a provided threat name and description. Insert gaps into the database where there is a strong reason to add a new item to the threat database. Respond OK if no changes are needed., Perplexity: 0.012881
Prompt: You identify whether there is a significant reason to update an inventory of threats based on a provided threat name and description. Insert gaps into the database where there is a strong reason to add a new item to the threat database. If there is no reason to update the database respond with OK., Perplexity: 0.032972
Prompt: Considering the new threat information provided, ascertain if an update is necessary for our threat database. Respond 'OK' if no changes are needed., Perplexity: 0.033821
**Prompt: You identify whether there is a significant reason to update an inventory of threats based on a provided threat name and description. Insert gaps into the database where there is a strong reason to add a new item to the threat database. If there is no reason to update the database respond with 'OK'., Perplexity: 0.034826**
Prompt: As an expert AI security analyst you identify whether there is a significant reason to update an inventory of threats based on a provided threat name and description. Insert gaps into the database where there is a strong reason to add a new item to the threat database. If there is no reason to update the database respond with OK., Perplexity: 0.035008
Prompt: As an expert AI security analyst you identify whether there is a significant reason to update an inventory of threats based on a provided threat name and description. Insert gaps into the database where there is a strong reason to add a new item to the threat database. If there is no reason to update the database respond with 'OK'., Perplexity: 0.037197
Prompt: Based on the provided threat name and description, determine if our threat inventory needs an update. If it doesn't, reply 'OK'., Perplexity: 0.047558
Two things stand out - one, inserting single quotes around ‘OK’ increases perplexity, and the phrasing Respond OK if no changes are needed is better than If there is no reason to update the database respond with OK.
However, just minimizing perplexity didn’t seriously change the quality of identified gaps.
Digging deeper with single examples revealed that the model has a hard time making a decision whether to make a function call or not depending on the criteria we specify, instead of placing this burden on the model, I simply put a boolean flag in the function spec to specify whether or not to add a threat. So, there’s no decision to be made whether to emit an insert - and all the reasoning can happen inside the domain of producing a well formed function call.
[[functions]]
name = "insert"
description = "Insert new threats in the database"
parameters = '''
{
"type": "object",
"required": [
"id",
"name",
"reason",
"insert"
],
"properties": {
"id": {
"type": "string",
"description": "The threat ID."
},
"name": {
"type": "string",
"description": "The name of the threat."
},
"reason": {
"type": "string",
"description": "Why the threat must be added."
},
"insert": {
"type": "boolean",
"description": "Whether or not the threat should be inserted."
}
}
}
'''
With these changes we net a more expected result given 559 CAPEC entries and 103 existing rules; 142 issues are flagged as covered and 416 are flagged as gaps. If you’re inclined and have the credit to spare you can compare chain-of-thought followed by an insert with this strategy head to head - let me know what results you get.
Threat condition statements
As suggested in Step 2: Generate PyTM rules from each gap the creation of fully-formed rules in one step is probably too complicated to do in one pass - as we can see in some examples of resulting ‘condition’ statements;
- ORM Injection:
target.controls.validatesInput is False - Exploit Non-Production Interfaces:
target.implementsAPI is True - Symlink Attack:
target.controls.validatesInput is False and target.controls.sanitizesInput is False
After fooling around (a key step) with single examples in the OpenAI playground, what becomes clear is that we need to split the task so that our first pass has the model reason about which properties / constraints to reason over, and our second actually generates the formed rule.
With this separation we get more elaborate conditional statements that are closer to what we need in a final rule;
- ORM Injection:
target.codeType in ['Hibernate', 'Entity Framework', 'Django ORM', 'Sequelize', 'SQLAlchemy'] and target.hasWriteAccess is True and target.data.isStored is True and (target.controls.sanitizesInput is False or target.controls.validatesInput is False or target.controls.implementsAuthenticationScheme is False or target.controls.implementsPOLP is False or target.controls.usesParameterizedInput is False) - Exploit Non-Production Interfaces:
target.environment != 'Production' or target.allowsClientSideScripting is True or target.usesCache is True or target.isShared is True - Symlink Attack:
target.codeType is not None and target.environment is not None and target.datastore.isShared is True and (target.controls.checksInputBounds is False or target.controls.sanitizesInput is False or target.controls.validatesInput is False or target.controls.implementsAuthenticationScheme is False or target.controls.hasAccessControl is False or target.controls.isHardened is False)
This much improved version is also available as an example in the ThoughLoom repository.
Impact
This is the first public example that shows how to use LLMs to identify gaps and generate AppSec tool rules. While this example focused on PyTM rulesets against CAPEC, it could have been CIS benchmarks, or some other technology focused risk inventory. Just as easily as we can swap the inputs, we can swap the targets - instead of PyTM we could do Semgrep rules. Perhaps you can imagine a trending topic on twitter kicking off this process? While these generated rules get a specialist engineer off ‘blank-page’ - they still aren’t ready to pipe directly into production. I expect that these techniques will first feed into ticket backlogs, be further enhanced with more LLM tool subdivision, each step enhanced with ensemble ranking, and each stage surrounded by robust testing harnesses and feedback mechanisms.
Working from here for open source or closed source projects means adopting this approach and building your own pipeline to help limited security engineers focus on producing value that scales to the world’s software. I hope those who read and learn from this article are inspired to do that work in the commons so that we can all benefit from those innovations.
Innovation distinguishes between a leader and a follower.
Not only is it theoretically possible to employ LLMs in a critical workflow that the safety of the world’s software relies on - the practical approach to doing so using readily available technology has been thoroughly demonstrated and documented in this article.