Hashcat'ing XenForo
Supporting the unsupported sha256(sha256($pass).$salt) hash type
Travis dropped
TL;DR - You can skip right to the results for the code.
A list that recently hit Hashes.org, with 1 million records and a low crack rate, looked like an interesting target, given that the community had recovered less than 0.5% of the list. On taking a closer look, we find out why;
Out of the box, only John the Ripper (JtR) Jumbo carries support for the XenForo hash scheme1 as a dynamic hash2.
[List.Generic:dynamic_1503]
Expression=sha256(sha256($p).$s) (XenForo SHA-256)
Flag=MGF_INPUT_32_BYTE
Flag=MGF_SALTED
Flag=MGF_FLAT_BUFFERS
Flag=MGF_KEYS_BASE16_IN1_SHA256
MaxInputLenX86=110
SaltLen=-120 // dont know, so made it big, jfoug
MaxInputLen=110
Func=DynamicFunc__set_input_len_64
Func=DynamicFunc__append_salt
Func=DynamicFunc__SHA256_crypt_input1_to_output1_FINAL
Test=$dynamic_1503$453f2e21fa6c150670d3ecf0e4a0ff3bab8b1903c2e96ad655d960b95f104248$697de9eda4a02563a7ec66d42d4a96995cb2948e29ab76fbcc89e8db71dd10f1:password
Test=$dynamic_1503$a8a0e9545c1475e8546f8546d87fe2516cf525c12ad79a6a7a8fee2fb0d8afd3$697de9eda4a02563a7ec66d42d4a96995cb2948e29ab76fbcc89e8db71dd10f1:verlongcrappypassword01234567890JtRJumbo’s XenForo definition.
JtR’s dynamic hashes don’t run on OpenCL, and a benchmark on a single core resulted in 4MH/s, while during a run we hit around 80MH/s across 20 CPU Cores. (H/T Solar Designer for the correction.)

What we had was a pretense for writing a custom OpenCL kernel for Hashcat—perfect. Adding to the effort was the lack of documentation around Hashcat (and sparse code comments).
My general methodology was running Hashcat in single-hash mode against the kernel and using printf() debugging statements to understand what was going on under the hood. Hashcat’s other kernels and its OpenSSL-style functions were definitely key to getting something working in a limited amount of time.
Orientation
./hashcat/include/interface.h3enumsand values required to add a new hash type../hashcat/src/interface.c4- Blocks that describe each hash type. It contains strings for Hashcat’s help function, as well as various constants and hash-parsing functions.
./hashcat/kernels/- Compiled OpenCL kernels. Hashcat compiles each OpenCL kernel at runtime and caches those kernels here.
./hashcat/OpenCL/5- OpenCL kernel sources (
.clfiles).
Play-by-play
let me smoke a cigarette, and I’ll tell you.
Inspiration
To start with, we identify an OpenCL a0 kernel (or set of kernels) that closely matches our workload and input type. For example, if your hash is salted, find a salted hash of the same type, and likewise if it is iterated.
Copy it to its own kernel file, designated as m[Hashcat Mode Flag]_a0-pure.cl. Search/replace this source to fix up the mode function names. In this guide, I used m01410_a0-pure.cl6 as the donor kernel. I’ll be using m01415_a0-pure.cl for the new mode 1415.
Adding the mode
Next up, add the new mode to Hashcat.
We add a new enum value SHA256_PW_SHA256_SLT to interface.h and set it equal to 1415:
KERN_TYPE_SHA256_PWSLT = 1410,
KERN_TYPE_SHA256_PW_SHA256_SLT = 1415,
KERN_TYPE_SHA256_SLTPW = 1420,Grabbing a new Hashcat -mode flag, 1415, for the XenForo mode.
HT_* is CLI / Help-related Text and a new entry HT_01415 is added to interface.c:
case 1411: return HT_01411;
case 1415: return HT_01415;
case 1420: return HT_01420;
static const char *HT_01410 = "sha256($pass.$salt)";
static const char *HT_01415 = "sha256(sha256($pass).$salt)";
static const char *HT_01420 = "sha256($salt.$pass)";Adding reference to our new XenForo mode in interface.c.
A test hash ST_HASH_01415 plus its corresponding plaintext ST_PASS_HASHCAT_PEANUT are used for self-testing:
static const char *ST_PASS_HASHCAT_PEANUT = "peanut";
…
static const char *ST_HASH_01415 = "00050655d5d6b8a8c14d52e852ce930fcd38e0551f161d71999860bba72e52aa:b4d93efdf7899fed0944a8bd19890a72764a9e169668d4c602fc6f1199eea449";
…
case 1411: hashconfig->hash_type = HASH_TYPE_SHA256;Adding a test hash and plaintext to interface.c.
And in the main hash configuration block, the values were lifted from case 1410:, sha256($plain.$salt).
An important bit here is to set kern_type to the enum added to interface.h, in this case KERN_TYPE_SHA256_PW_SHA256_SLT. parse_func is a function pointer, set to sha256s_parse_hash - which will be invoked to parse the hash list. If your hash format can’t be consumed by these functions exactly, it will be rejected. Hashcat has a robust set of these parsing functions, and you’ll want to hunt through them in interface.c7.
case 1411: hashconfig->hash_type = HASH_TYPE_SHA256;
...
break;
case 1415: hashconfig->hash_type = HASH_TYPE_SHA256;
hashconfig->salt_type = SALT_TYPE_GENERIC;
hashconfig->attack_exec = ATTACK_EXEC_INSIDE_KERNEL;
hashconfig->opts_type = OPTS_TYPE_PT_GENERATE_BE
| OPTS_TYPE_ST_ADD80
| OPTS_TYPE_ST_ADDBITS15;
hashconfig->kern_type = KERN_TYPE_SHA256_PW_SHA256_SLT;
hashconfig->dgst_size = DGST_SIZE_4_8;
hashconfig->parse_func = sha256s_parse_hash;
hashconfig->opti_type = OPTI_TYPE_ZERO_BYTE
| OPTI_TYPE_PRECOMPUTE_INIT
| OPTI_TYPE_PRECOMPUTE_MERKLE
| OPTI_TYPE_EARLY_SKIP
| OPTI_TYPE_NOT_ITERATED
| OPTI_TYPE_APPENDED_SALT
| OPTI_TYPE_RAW_HASH;
hashconfig->dgst_pos0 = 3;
hashconfig->dgst_pos1 = 7;
hashconfig->dgst_pos2 = 2;
hashconfig->dgst_pos3 = 6;
hashconfig->st_hash = ST_HASH_01415;
hashconfig->st_pass = ST_PASS_HASHCAT_PEANUT;
break;The final configuration block in interface.c.
Quick and dirty test
After a make clean && make, Hashcat should list your new type. Benchmark mode won’t be useful for testing, as the a0 kernels aren’t used here. Running a simple single-hash test against the new kernel will cause Hashcat to build it from the OpenCL directory to the kernels directory. This is when you’ll receive compile-time errors.
In this case, I had known hash/salt/plaintext values (recoverable from JtR and publicly listed). These are essential. You’ll find out how to use the raw results of intermediate steps in the scheme for debugging in the next section.
I used this example for testing:
00050655d5d6b8a8c14d52e852ce930fcd38e0551f161d71999860bba72e52aa:b4d93efdf7899fed0944a8bd19890a72764a9e169668d4c602fc6f1199eea449:peanutSample XenForo hash, salt, and plaintext tuple - for the plaintext ‘peanut’. The format is [hash]:[salt]:[plaintext].
Steps from the command line:
## echo -n peanut | shasum -a 256
5509840d0873adb0405588821197a8634501293486c601ca51e14063abe25d06 –
## echo -n 5509840d0873adb0405588821197a8634501293486c601ca51e14063abe25d06b4d93efdf7899fed0944a8bd19890a72764a9e169668d4c602fc6f1199eea449 | shasum -a 256
00050655d5d6b8a8c14d52e852ce930fcd38e0551f161d71999860bba72e52aa –Re-create the sample hash for ‘peanut’ using shasum. This confirms our scheme.
Reviewing; with the $salt value b4d93efdf7899fed0944a8bd19890a72764a9e169668d4c602fc6f1199eea449 where sha256('peanut') is 5509840d0873adb0405588821197a8634501293486c601ca51e14063abe25d06 and sha256(sha256('peanut') . $salt) is 00050655d5d6b8a8c14d52e852ce930fcd38e0551f161d71999860bba72e52aa. As expected by sha256(sha256($pass).$salt).
Hashcat test:
## ./hashcat -m 1415 -a 0 “00050655d5d6b8a8c14d52e852ce930fcd38e0551f161d71999860bba72e52aa:b4d93efdf7899fed0944a8bd19890a72764a9e169668d4c602fc6f1199eea449” peanut.txt
hashcat (v4.0.1-123-g2095e27d+) starting…
OpenCL Platform #1: Apple
=========================
* Device #1: Intel(R) Core(TM) i7-6920HQ CPU @ 2.90GHz, skipped.
* Device #2: Intel(R) HD Graphics 530, 384/1536 MB allocatable, 24MCU
* Device #3: AMD Radeon Pro 460 Compute Engine, 1024/4096 MB allocatable, 16MCU
…
Watchdog: Temperature abort trigger disabled.
* Device #2: ATTENTION! OpenCL kernel self-test failed.
Your device driver installation is probably broken.
See also: https://hashcat.net/faq/wrongdriver
* Device #3: ATTENTION! OpenCL kernel self-test failed.
Your device driver installation is probably broken.
See also: https://hashcat.net/faq/wrongdriverTesting our new -mode 1415’s -a 0 kernel. peanut.txt contains the word ‘peanut’.
We now have a custom Hashcat build that lists our new type. Awesome. Let’s get these self-tests to pass with a single hash.
Kicking out the jams
You gotta have it, baby, you can’t do without
Oh, when you get that feeling you gotta sock ’em out
The majority of the work on an a0 kernel will be focused on these two functions:
__kernel void m01415_mxx- Invoked to handle cracking multiple target hashes at once. We can ignore this during testing.
__kernel void m01415_sxx- Invoked in single-hash mode (which is how we’re testing). We can focus our development effort here.
Let’s take a walk through the donor kernel’s m01410_sxx function:
/**
* digest
*/
const u32 search[4] =
{
digests_buf[digests_offset].digest_buf[DGST_R0],
digests_buf[digests_offset].digest_buf[DGST_R1],
digests_buf[digests_offset].digest_buf[DGST_R2],
digests_buf[digests_offset].digest_buf[DGST_R3]
};The first block of the m01410_sxx function.
In this kernel, Hashcat doesn’t bother comparing all the bytes in the hash buffer — a basic optimization technique. It’s unlikely to collide with a human-meaningful candidate as selected by Hashcat, even when doing partial matches. The bytes are configured in the dgst_pos* values of the hashconfig struct:
hashconfig->dgst_pos0 = 3;
hashconfig->dgst_pos1 = 7;
hashconfig->dgst_pos2 = 2;
hashconfig->dgst_pos3 = 6;Our mode’s dgst_pos* values from interface.c.
Use values from another kernel that has the same final hash round as your target.
/**
* base
*/
COPY_PW (pws[gid]);
const u32 salt_len = salt_bufs[salt_pos].salt_len;
u32 s[64] = { 0 };
for (int i = 0, idx = 0; i < salt_len; i += 4, idx += 1)
{
s[idx] = swap32_S (salt_bufs[salt_pos].salt_buf[idx]);
}m01410_sxx preps s[] for sha256 so it can be appended before finalization.
The kernel prepares the salt buffer once and carries out operations usually performed by the Hashcat sha256 library’s sha256_update_swap function.
Now is a good time to browse through the methods in inc_hash_sha256.cl8. These aren’t documented in any way, and while they resemble other low-level C crypto implementations, some things have been changed to permit more efficient cracking. It helps to select methods out of this library, and those in its hash family (e.g., sha512, sha1), to understand how these functions can be used in various contexts.9
/**
* loop
*/
for (u32 il_pos = 0; il_pos < il_cnt; il_pos++)
{
pw_t tmp = PASTE_PW;
tmp.pw_len = apply_rules (rules_buf[il_pos].cmds, tmp.i, tmp.pw_len);
sha256_ctx_t ctx;
sha256_init (&ctx);
sha256_update_swap (&ctx, tmp.i, tmp.pw_len);
sha256_update (&ctx, s, salt_len);
sha256_final (&ctx);
const u32 r0 = ctx.h[DGST_R0];
const u32 r1 = ctx.h[DGST_R1];
const u32 r2 = ctx.h[DGST_R2];
const u32 r3 = ctx.h[DGST_R3];
COMPARE_S_SCALAR (r0, r1, r2, r3);
}m01410_sxx calculates plaintext candidate hashes according to rules.
The function’s main loop permutes the password root candidate tmp.i according to rules identified in the rules_buf array. It then establishes a sha256 context, updates the context with the password candidate buffer, updates it (minus the swap already performed) with the salt, and then finalizes the hash. It then compares the bytes outlined in hashconfig->dgst_pos* for a match.
Because our source function is sha256($plain.$salt) and our target is sha256(sha256($plain).$salt), we know we need to add a round of sha256 to the plaintext before updating the final sha256 context, ctx.
Check out some other modes that might carry out similar operations…
| Mode | Algorithm | Type |
|---|---|---|
| 40 | md5($salt.utf16le($pass)) |
raw hash, salted, and/or iterated |
| 3710 | md5($salt.md5($pass)) |
raw hash, salted, and/or iterated |
| 140 | sha1($salt.utf16le($pass)) |
raw hash, salted, and/or iterated |
| 4520 | sha1($salt.sha1($pass)) |
raw hash, salted, and/or iterated |
| 1440 | sha256($salt.utf16le($pass)) |
raw hash, salted, and/or iterated |
| 1740 | sha512($salt.utf16le($pass)) |
raw hash, salted, and/or iterated |
| 30 | md5(utf16le($pass).$salt) |
raw hash, salted, and/or iterated |
| 130 | sha1(utf16le($pass).$salt) |
raw hash, salted, and/or iterated |
| 1430 | sha256(utf16le($pass).$salt) |
raw hash, salted, and/or iterated |
| 1730 | sha512(utf16le($pass).$salt) |
raw hash, salted, and/or iterated |
Some nice candidates include m02610_a0-pure.cl, m04700_a0-pure.cl, m04520_a0-pure.cl, m04500_a0-pure.cl, and m04400_a0-pure.cl. This builds up more examples of how the Hashcat developers used the libraries and OpenCL environment efficiently.
Let’s take a look at an example of a salted hash, with an extra round of hash on the plaintext. Thankfully, we have one in the same hash family: 452010, sha1($salt.sha1($pass)).
Here’s the core routine:
sha1_ctx_t ctx1;
sha1_init (&ctx1);
sha1_update_swap (&ctx1, tmp.i, tmp.pw_len);
sha1_final (&ctx1);
const u32 a = ctx1.h[0];
const u32 b = ctx1.h[1];
const u32 c = ctx1.h[2];
const u32 d = ctx1.h[3];
const u32 e = ctx1.h[4];
sha1_ctx_t ctx = ctx0;
u32 w0[4];
u32 w1[4];
u32 w2[4];
u32 w3[4];
w0[0] = uint_to_hex_lower8_le ((a >> 16) & 255) << 0
| uint_to_hex_lower8_le ((a >> 24) & 255) << 16;
w0[1] = uint_to_hex_lower8_le ((a >> 0) & 255) << 0
| uint_to_hex_lower8_le ((a >> 8) & 255) << 16;
w0[2] = uint_to_hex_lower8_le ((b >> 16) & 255) << 0
| uint_to_hex_lower8_le ((b >> 24) & 255) << 16;
w0[3] = uint_to_hex_lower8_le ((b >> 0) & 255) << 0
| uint_to_hex_lower8_le ((b >> 8) & 255) << 16;
w1[0] = uint_to_hex_lower8_le ((c >> 16) & 255) << 0
| uint_to_hex_lower8_le ((c >> 24) & 255) << 16;
w1[1] = uint_to_hex_lower8_le ((c >> 0) & 255) << 0
| uint_to_hex_lower8_le ((c >> 8) & 255) << 16;
w1[2] = uint_to_hex_lower8_le ((d >> 16) & 255) << 0
| uint_to_hex_lower8_le ((d >> 24) & 255) << 16;
w1[3] = uint_to_hex_lower8_le ((d >> 0) & 255) << 0
| uint_to_hex_lower8_le ((d >> 8) & 255) << 16;
w2[0] = uint_to_hex_lower8_le ((e >> 16) & 255) << 0
| uint_to_hex_lower8_le ((e >> 24) & 255) << 16;
w2[1] = uint_to_hex_lower8_le ((e >> 0) & 255) << 0
| uint_to_hex_lower8_le ((e >> 8) & 255) << 16;
w2[2] = 0;
w2[3] = 0;
w3[0] = 0;
w3[1] = 0;
w3[2] = 0;
w3[3] = 0;
sha1_update_64 (&ctx, w0, w1, w2, w3, 40);
sha1_final (&ctx);m04520_a0-pure’s main loop.
We can see that this routine uses two sha1 contexts: ctx1 to contain sha1($pass) and ctx to contain sha1($salt.sha1($pass)). Additionally, this kernel introduces a new macro, uint_to_hex_lower8_le, and adds some logic to the *_sxx function:
const u64 lsz = get_local_size (0);
/**
* bin2asc table
*/
__local u32 l_bin2asc[256];
for (u32 i = lid; i < 256; i += lsz)
{
const u32 i0 = (i >> 0) & 15;
const u32 i1 = (i >> 4) & 15;
l_bin2asc[i] = ((i0 < 10) ? ‘0’ + i0 : ‘a’ – 10 + i0) << 0
| ((i1 < 10) ? ‘0’ + i1 : ‘a’ – 10 + i1) << 8;
}bin2asc is a binary to ASCII hex lookup array.
uint_to_hex_lower8_le looks up a byte in l_bin2asc, which returns a lowercase ASCII representation in 2 bytes. We rely on this to convert the raw hex output of the first sha1 round to the lowercase ASCII representation that is usually composed in these salted routines.
The next step is understanding how to use this construct for sha256. We can find that sha1 has an output of 40 bytes, while sha256 outputs 64 bytes. Let’s set this up in our new kernel. First, add the uint_to_hex_lower8_le macro to the beginning of the file. Then add the routine to build the l_bin2asc array. Next, let’s change the core crack routine:
/**
* loop
*/
for (u32 il_pos = 0; il_pos < il_cnt; il_pos++)
{
pw_t tmp = PASTE_PW;
tmp.pw_len = apply_rules (rules_buf[il_pos].cmds, tmp.i, tmp.pw_len);
sha256_ctx_t ctx; //containing the final context
sha256_init (&ctx);
sha256_ctx_t ctx1; //containing the sha256($pass) context
sha256_init (&ctx1);
sha256_update_swap (&ctx1, tmp.i, tmp.pw_len);
sha256_final (&ctx1); //finalize the sha256 rounds.
const u32 a = ctx1.h[0];
const u32 b = ctx1.h[1];
const u32 c = ctx1.h[2];
const u32 d = ctx1.h[3];
const u32 e = ctx1.h[4];
u32 w0[4];
u32 w1[4];
u32 w2[4];
u32 w3[4];
w0[0] = uint_to_hex_lower8_le ((a >> 16) & 255) << 0
| uint_to_hex_lower8_le ((a >> 24) & 255) << 16;
w0[1] = uint_to_hex_lower8_le ((a >> 0) & 255) << 0
| uint_to_hex_lower8_le ((a >> 8) & 255) << 16;
w0[2] = uint_to_hex_lower8_le ((b >> 16) & 255) << 0
| uint_to_hex_lower8_le ((b >> 24) & 255) << 16;
w0[3] = uint_to_hex_lower8_le ((b >> 0) & 255) << 0
| uint_to_hex_lower8_le ((b >> 8) & 255) << 16;
w1[0] = uint_to_hex_lower8_le ((c >> 16) & 255) << 0
| uint_to_hex_lower8_le ((c >> 24) & 255) << 16;
w1[1] = uint_to_hex_lower8_le ((c >> 0) & 255) << 0
| uint_to_hex_lower8_le ((c >> 8) & 255) << 16;
w1[2] = uint_to_hex_lower8_le ((d >> 16) & 255) << 0
| uint_to_hex_lower8_le ((d >> 24) & 255) << 16;
w1[3] = uint_to_hex_lower8_le ((d >> 0) & 255) << 0
| uint_to_hex_lower8_le ((d >> 8) & 255) << 16;
w2[0] = uint_to_hex_lower8_le ((e >> 16) & 255) << 0
| uint_to_hex_lower8_le ((e >> 24) & 255) << 16;
w2[1] = uint_to_hex_lower8_le ((e >> 0) & 255) << 0
| uint_to_hex_lower8_le ((e >> 8) & 255) << 16;
w2[2] = 0;
w2[3] = 0;
w3[0] = 0;
w3[1] = 0;
w3[2] = 0;
w3[3] = 0;
sha256_update_64 (&ctx, w0, w1, w2, w3, 40); // prepend the internal sha256 hash.
sha256_update (&ctx, s, salt_len); // add the salt
sha256_final (&ctx); // finalize
const u32 r0 = ctx.h[DGST_R0];
const u32 r1 = ctx.h[DGST_R1];
const u32 r2 = ctx.h[DGST_R2];
const u32 r3 = ctx.h[DGST_R3];
COMPARE_S_SCALAR (r0, r1, r2, r3);
}The new main loop for our XenForo kernel.
Next up, we need to address the extra bytes available in sha256’s output:
const u32 a = ctx1.h[0];
const u32 b = ctx1.h[1];
const u32 c = ctx1.h[2];
const u32 d = ctx1.h[3];
const u32 e = ctx1.h[4];
const u32 a1 = ctx1.h[5];
const u32 b1 = ctx1.h[6];
const u32 c1 = ctx1.h[7];
u32 w0[4];
u32 w1[4];
u32 w2[4];
u32 w3[4];
w0[0] = uint_to_hex_lower8_le ((a >> 16) & 255) << 0
| uint_to_hex_lower8_le ((a >> 24) & 255) << 16;
w0[1] = uint_to_hex_lower8_le ((a >> 0) & 255) << 0
| uint_to_hex_lower8_le ((a >> 8) & 255) << 16;
w0[2] = uint_to_hex_lower8_le ((b >> 16) & 255) << 0
| uint_to_hex_lower8_le ((b >> 24) & 255) << 16;
w0[3] = uint_to_hex_lower8_le ((b >> 0) & 255) << 0
| uint_to_hex_lower8_le ((b >> 8) & 255) << 16;
w1[0] = uint_to_hex_lower8_le ((c >> 16) & 255) << 0
| uint_to_hex_lower8_le ((c >> 24) & 255) << 16;
w1[1] = uint_to_hex_lower8_le ((c >> 0) & 255) << 0
| uint_to_hex_lower8_le ((c >> 8) & 255) << 16;
w1[2] = uint_to_hex_lower8_le ((d >> 16) & 255) << 0
| uint_to_hex_lower8_le ((d >> 24) & 255) << 16;
w1[3] = uint_to_hex_lower8_le ((d >> 0) & 255) << 0
| uint_to_hex_lower8_le ((d >> 8) & 255) << 16;
w2[0] = uint_to_hex_lower8_le ((e >> 16) & 255) << 0
| uint_to_hex_lower8_le ((e >> 24) & 255) << 16;
w2[1] = uint_to_hex_lower8_le ((e >> 0) & 255) << 0
| uint_to_hex_lower8_le ((e >> 8) & 255) << 16;
w2[2] = uint_to_hex_lower8_le ((a1 >> 16) & 255) << 0
| uint_to_hex_lower8_le ((a1 >> 24) & 255) << 16;
w2[3] = uint_to_hex_lower8_le ((a1 >> 0) & 255) << 0
| uint_to_hex_lower8_le ((a1 >> 8) & 255) << 16;
w3[0] = uint_to_hex_lower8_le ((b1 >> 16) & 255) << 0
| uint_to_hex_lower8_le ((b1 >> 24) & 255) << 16;
w3[1] = uint_to_hex_lower8_le ((b1 >> 0) & 255) << 0
| uint_to_hex_lower8_le ((b1 >> 8) & 255) << 16;
w3[2] = uint_to_hex_lower8_le ((c1 >> 16) & 255) << 0
| uint_to_hex_lower8_le ((c1 >> 24) & 255) << 16;
w3[3] = uint_to_hex_lower8_le ((c1 >> 0) & 255) << 0
| uint_to_hex_lower8_le ((c1 >> 8) & 255) << 16;
sha256_update_64 (&ctx, w0, w1, w2, w3, 64); // prepend the internal sha256 hash.
For real this time. Now with a1, b1, and c1.
In my case, it took a few attempts to get the bit shifting / byte ordering correct. Here’s what I did:
We know, ultimately, that w0, w1, w2, and w3 needed to hold the ASCII representation of the sha256 hash, using our example ‘peanut’:
# echo -n peanut | shasum -a 256 | xxd
00000000: 3535 3039 3834 3064 3038 3733 6164 6230 5509840d0873adb0
00000010: 3430 3535 3838 3832 3131 3937 6138 3633 405588821197a863
00000020: 3435 3031 3239 3334 3836 6336 3031 6361 4501293486c601ca
00000030: 3531 6531 3430 3633 6162 6532 3564 3036 51e14063abe25d06
00000040: 2020 2d0aGrabbing the bytes for the intermediate sha256('peanut') step using xxd.
The correct array would look like this:
w0[0] = 0x35353039;
w0[1] = 0x38343064;
w0[2] = 0x30383733;
w0[3] = 0x61646230;
w1[0] = 0x34303535;
w1[1] = 0x38383832;
w1[2] = 0x31313937;
w1[3] = 0x61383633;
w2[0] = 0x34353031;
w2[1] = 0x32393334;
w2[2] = 0x38366336;
w2[3] = 0x30316361;
w3[0] = 0x35316531;
w3[1] = 0x34303633;
w3[2] = 0x61626532;
w3[3] = 0x35643036;Hardcoded array for debugging byte-order.
Using these hardcoded values, Hashcat passes the self-test… Progress!
We can play with byte ordering and bit shifting until w0[0] holds 0x35353039 (which, unless you’re shifting on a regular basis, isn’t natural):
w0[0] = uint_to_hex_lower8_le ((a >> 16) & 255) << 0
| uint_to_hex_lower8_le ((a >> 24) & 255) << 16; //0x35353039;
w0[1] = 0x38343064;
w0[2] = 0x30383733;
w0[3] = 0x61646230;
w1[0] = 0x34303535;
w1[1] = 0x38383832;
w1[2] = 0x31313937;
w1[3] = 0x61383633;
w2[0] = 0x34353031;
w2[1] = 0x32393334;
w2[2] = 0x38366336;
w2[3] = 0x30316361;
w3[0] = 0x35316531;
w3[1] = 0x34303633;
w3[2] = 0x61626532;
w3[3] = 0x35643036;
printf(“\na = 0x%08x, w0[0]=0x%08x\n”, a,w0[0]); // debug
Everything but w0[0] is hardcoded. The printf helps us sort the right ordering.
You can debug the kernel by alternating rm -rf ./hashcat/kernels with your Hashcat single-hash test command e.g. ./hashcat -m 1415 -a 0 “00050655d5d6b8a8c14d52e852ce930fcd38e0551f161d71999860bba72e52aa:b4d93efdf7899fed0944a8bd19890a72764a9e169668d4c602fc6f1199eea449” peanut.txt. This is how I nailed down byte ordering and conversion.
With the right values in w0, w1, w2, and w3, we can move the *_sxx changes over to *_mxx. Just reapply your changes there while making sure the final comparison function is COMPARE_M instead of COMPARE_S.
Results
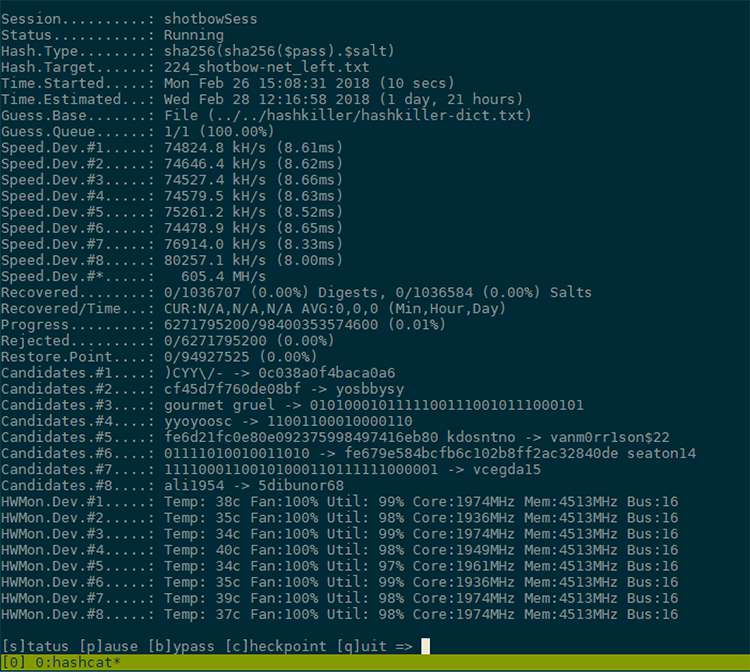
On an eight Nvidia 1080 GPU cracking rig from sagitta, we hit 605 MH/s with this unoptimized kernel — 7 times faster than CPU mode.
I’ll need to wait for another rainy day (and a corpus with a shorter salt) to hack on an optimized kernel.
You can find the final implementation at this GitHub Gist.
-
https://github.com/magnumripper/JohnTheRipper/blob/323f4babdefadfae99568474557dacc2a130d8b3/run/dynamic.conf#L945 ↩︎
-
https://github.com/magnumripper/JohnTheRipper/blob/bleeding-jumbo/doc/DYNAMIC ↩︎
-
https://github.com/hashcat/hashcat/blob/master/include/interface.h ↩︎
-
https://github.com/hashcat/hashcat/blob/master/src/interface.c ↩︎
-
https://github.com/hashcat/hashcat/blob/master/OpenCL/m01410_a0-pure.cl ↩︎
-
https://github.com/hashcat/hashcat/blob/dbbba1fbdf05403675ddbf7d3b36f42ab7b76f68/include/interface.h#L1509 ↩︎
-
https://github.com/hashcat/hashcat/blob/master/OpenCL/inc_hash_sha256.cl ↩︎
-
https://github.com/hashcat/hashcat/search?q=inc_hash_sha256.cl ↩︎
-
https://github.com/hashcat/hashcat/blob/master/OpenCL/m04520_a0-pure.cl ↩︎